SSL code explain
In this post. We explain the SSL training code.
def open_tif(fn, cls=torch.Tensor):
im = skio.imread(str(fn))/10000
im = im.transpose(1,2,0).astype('float32')
return im
img=open_tif('./tifs/S2B_MSIL2A_20170924T093019_45_63.tif')
plt.imshow(img[:,:,3])

BAND_STATS = {
'S2':{
'mean': {
'B01': 340.76769064,
'B02': 429.9430203,
'B03': 614.21682446,
'B04': 590.23569706,
'B05': 950.68368468,
'B06': 1792.46290469,
'B07': 2075.46795189,
'B08': 2218.94553375,
'B8A': 2266.46036911,
'B09': 2246.0605464,
'B11': 1594.42694882,
'B12': 1009.32729131
},
'std': {
'B01': 554.81258967,
'B02': 572.41639287,
'B03': 582.87945694,
'B04': 675.88746967,
'B05': 729.89827633,
'B06': 1096.01480586,
'B07': 1273.45393088,
'B08': 1365.45589904,
'B8A': 1356.13789355,
'B09': 1302.3292881,
'B11': 1079.19066363,
'B12': 818.86747235
}
},
'S1': {
'mean': {
'VV': -12.619993741972035,
'VH': -19.29044597721542,
'VV/VH': 0.6525036195871579,
},
'std': {
'VV': 5.115911777546365,
'VH': 5.464428464912864,
'VV/VH': 30.75264076801808,
},
'min': {
'VV': -74.33214569091797,
'VH': -75.11137390136719,
'R': 3.21E-2
},
'max': {
'VV': 34.60696029663086,
'VH': 33.59768295288086,
'R': 1.08
}
}
}
bands=['B02','B03', 'B04', 'B05','B06', 'B07', 'B11', 'B08','B8A', 'B12']
means=[BAND_STATS['S2']['mean'][band]/10000 for band in bands]
stds=[BAND_STATS['S2']['std'][band]/10000 for band in bands]
img=open_tif('./tifs/S2B_MSIL2A_20170924T093019_45_63.tif')
plt.imshow(img[:,:,0])

from albumentations.core.transforms_interface import ImageOnlyTransform
import random
class Channelaug(ImageOnlyTransform):
def __init__(self, always_apply=False, p=0.5):
super(Channelaug, self).__init__(always_apply, p)
def apply(self, img, **params):
temp=img[:,:,random.randint(0,9),np.newaxis]
return np.repeat(temp,10,axis=2)
import albumentations as A
from albumentations.pytorch import ToTensorV2
from torchvision import transforms
trainaug=[]
# first gobal crop
globalaug1 = A.Compose([
Channelaug(always_apply=True),
A.HorizontalFlip(p=0.5),
A.ShiftScaleRotate(p=.5),
A.RandomResizedCrop(120,120,scale=(0.4, 1.)),
A.GaussianBlur(p=1.0),
# A.Solarize(threshold=0.5),
A.Normalize(mean=means,std=stds,max_pixel_value=1.0),
ToTensorV2()]
)
# second global crop
globalaug2 = A.Compose([A.HorizontalFlip(p=0.5),
A.ShiftScaleRotate(p=.5),
A.RandomResizedCrop(120,120,scale=(0.4, 1.)),
A.GaussianBlur(p=0.1),
A.Solarize(threshold=0.5,p=0.2),
A.Normalize(mean=means,std=stds,max_pixel_value=1.0),
ToTensorV2()]
)
# transformation for the local small crops
locaaug = A.Compose([A.HorizontalFlip(p=0.5),
A.ShiftScaleRotate(p=.5),
A.RandomResizedCrop(56,56,scale=(0.05, 0.4),always_apply=True),
A.GaussianBlur(p=0.5),
A.Normalize(mean=means,std=stds,max_pixel_value=1.0),
ToTensorV2()]
)
trainaug.append(globalaug1)
trainaug.append(globalaug2)
for _ in range(6):
trainaug.append(locaaug)
result=[]
for i in range(len(trainaug)):
result.append(trainaug[i](image=img)['image'])
aug=Channelaug(always_apply=True)
xx=aug(image=img)['image']
fig, axs = plt.subplots(2,4,dpi=150)
for i in range(8):
axs[i//4,i%4].imshow(result[i][3])

MultiCropWrapper
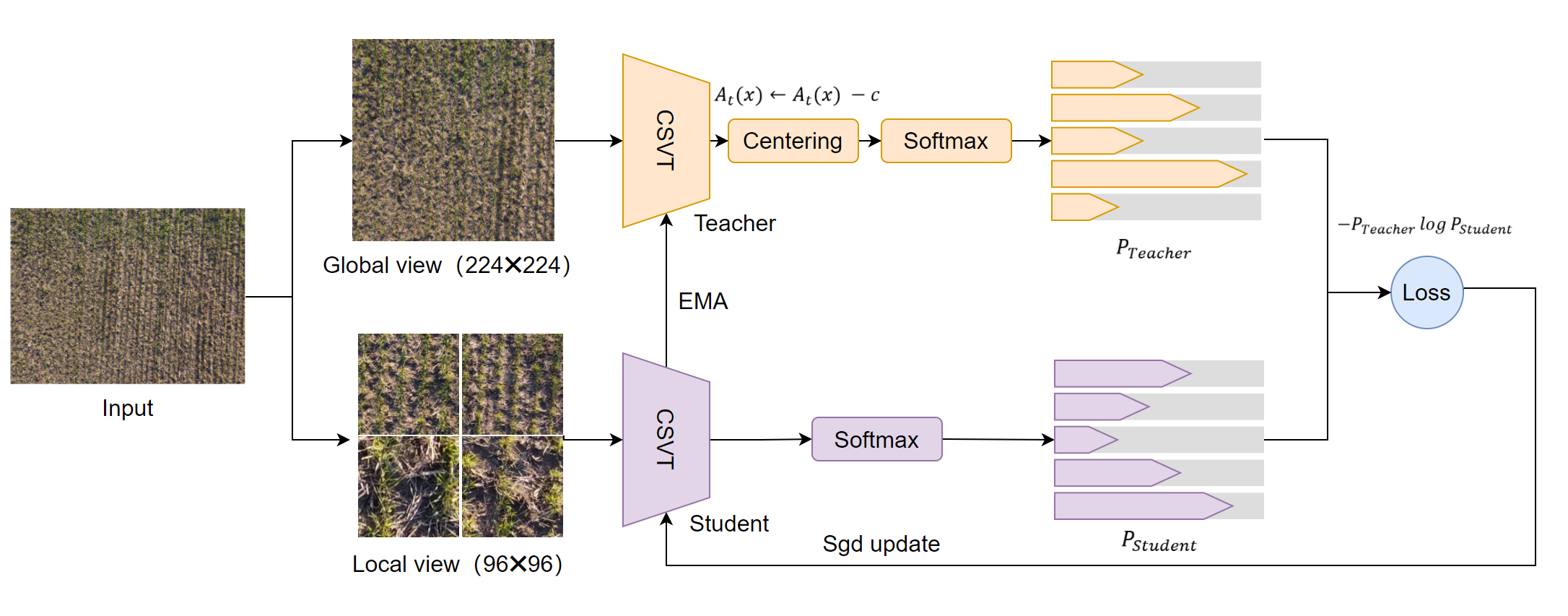
Perform forward pass separately on each resolution input.The inputs corresponding to a single resolution are clubbed and single forward is run on the same resolution inputs. Hence we do several forward passes = number of different resolutions used. We then concatenate all the output features and run the head forward on these concatenated features.
class MultiCropWrapper(nn.Module):
def __init__(self, backbone, head):
super(MultiCropWrapper, self).__init__()
# disable layers dedicated to ImageNet labels classification
backbone.fc, backbone.head = nn.Identity(), nn.Identity()
self.backbone = backbone
self.head = head
def forward(self, x):
# convert to list
if not isinstance(x, list):
x = [x]
idx_crops = torch.cumsum(torch.unique_consecutive(
torch.tensor([inp.shape[-1] for inp in x]),
return_counts=True,
)[1], 0)
start_idx, output = 0, torch.empty(0).to(x[0].device)
for end_idx in idx_crops:
_out = self.backbone(torch.cat(x[start_idx: end_idx]))
# The output is a tuple with XCiT model. See:
# https://github.com/facebookresearch/xcit/blob/master/xcit.py#L404-L405
if isinstance(_out, tuple):
_out = _out[0]
# accumulate outputs
output = torch.cat((output, _out))
start_idx = end_idx
# Run the head forward on the concatenated features.
return self.head(output)
teacher_output = teacher(images[:2])
student_output = student(images)
loss = dino_loss(student_output, teacher_output, epoch)
# EMA update for the teacher
with torch.no_grad():
m = momentum_schedule[it] # momentum parameter
for param_q, param_k in zip(student.module.parameters(), teacher_without_ddp.parameters()):
param_k.data.mul_(m).add_((1 - m) * param_q.detach().data)
Two golbal views are fed to teacher and all the others are fed to student
class DINOLoss(nn.Module):
def __init__(self, out_dim, ncrops, warmup_teacher_temp, teacher_temp,
warmup_teacher_temp_epochs, nepochs, student_temp=0.1,
center_momentum=0.9):
super().__init__()
self.student_temp = student_temp
self.center_momentum = center_momentum
self.ncrops = ncrops
self.register_buffer("center", torch.zeros(1, out_dim))
# we apply a warm up for the teacher temperature because
# a too high temperature makes the training instable at the beginning
self.teacher_temp_schedule = np.concatenate((
np.linspace(warmup_teacher_temp,
teacher_temp, warmup_teacher_temp_epochs),
np.ones(nepochs - warmup_teacher_temp_epochs) * teacher_temp
))
def forward(self, student_output, teacher_output, epoch):
"""
Cross-entropy between softmax outputs of the teacher and student networks.
"""
student_out = student_output / self.student_temp
student_out = student_out.chunk(self.ncrops)
# teacher centering and sharpening
temp = self.teacher_temp_schedule[epoch]
teacher_out = F.softmax((teacher_output - self.center) / temp, dim=-1)
teacher_out = teacher_out.detach().chunk(2)
total_loss = 0
n_loss_terms = 0
for iq, q in enumerate(teacher_out):
for v in range(len(student_out)):
if v == iq:
# we skip cases where student and teacher operate on the same view
continue
loss = torch.sum(-q * F.log_softmax(student_out[v], dim=-1), dim=-1)
total_loss += loss.mean()
n_loss_terms += 1
total_loss /= n_loss_terms
self.update_center(teacher_output)
return total_loss
@torch.no_grad()
def update_center(self, teacher_output):
"""
Update center used for teacher output.
"""
batch_center = torch.sum(teacher_output, dim=0, keepdim=True)
dist.all_reduce(batch_center)
batch_center = batch_center / (len(teacher_output) * dist.get_world_size())
# ema update
self.center = self.center * self.center_momentum + batch_center * (1 - self.center_momentum)